Node.js Pull Request Merge Prediction Using Machine Learning
Ignacio Avas
January 15, 2018

In this article I will explain a simple use of machine learning (ML) to see if it is possible to accurately predict whether a pull request (PR) will be accepted when it is created. The aim of this experiment is to generate a reliable program which can aid a project integrator in managing PRs for a particular project. Considering that large software projects have a constant flow of new PRs, this work explores a replicable model to help filter out unwanted pull requests as soon as possible.
Previous work by Yu et al.1, and Gousios et al.2 propose prediction models that account for a set of repositories to predict the PR acceptance, even if the PR doesn't belong to the set of training projects used to train the model. This leads to a lower accuracy in the prediction, especially if the model was trained using data from Project A and B, and then you try to predict acceptance from project C. The model may use decision criteria that is wrong for project C. However, the proposed approach only uses data from the project the PR belongs to. Here, we aim to predict Nodejs PRs using data available at the time the PR is submitted in order to evaluate if it is going to be merged or not immediately upon submission.
Building the predictor
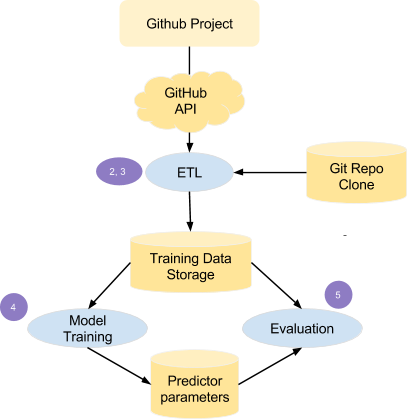
To make predictions about PR, we need to create a predictor and find the right set of parameters for our problem. We used the following steps to build the program:
- Define relevant features to evaluate a PR.
- Gather data from Github data sources for the desired project.
- Normalize relevant data into a persistent data store to input for ML prediction models.
- Choose the prediction model that works best with the gathered data
- Evaluate the chosen predictor on a separate data set.
Defining features
For step 1, the definition of relevant features is based on existing work by Yu et al. We used the following features:
description_complexity
|
Number of words in the description and title. A longer description might lead to a more complex PR, more difficult for reviewers to approve due to many features. |
log_hotness
|
Refers to the Project Area Hotness number H: H is the number of files committed in the last 3 months which are also included in the PR. This feature takes the value log(1 + H). A higher Hotness may suggest too many PR touching core files, which might be controversial.
|
log_churn
|
Refers to the PR Churn C: The sum of deleted, modified and added lines in the PR. This feature takes the value log(1 + H).
|
is_integrator
|
Indicates if the author of the PR is a project integrator: a person which merged the PR at least once in the history of the Project. Integrators are more likely to publish successful PRs. This feature is 1 or 0 depending on whether or not the author is an integrator. |
has_tests
|
Indicates if the PR includes tests, which in turn might benefit the chances of approval. This feature value is either 1 or 0 depending on whether the PR has tests. This is computed based on whether an added or modified file is a test by matching the filename against a set of regular expressions. |
success_rate
|
A number related to the previous acceptance of the author PRs. This is the coefficient of approved versus submitted PRs. A higher success rate might suggest the PR will be accepted. |
social_conn
|
Sum of followers and following of the author of the PR. An author with more social connection might be more successful. |
requested_reviewers
|
Indicates if the author requested any reviewer. This is a good measure to suggest if the author cares about the PR's acceptance. The inclusion of a reviewer may increase the chance of being accepted. |
created_friday
|
Requests created on Friday are more likely to not be accepted or to be accepted later due to the weekend, leading to a larger PR queue. |
Future work might include a greater feature set like the compliance of project-specific commit message requirements, whether the PR passes unit tests, number of open pull requests at that time, just to name a few. Also, it may be useful to account for chronological data, because compliance requirements change over time, and an old PR would have been judged with different standards than new PRs. Time based datasets classification is a common problem in ML, because classification criteria depends on the time the data was created and classified. Brownlee3 shows a way to deal with forecasting data in ML.
ETL load
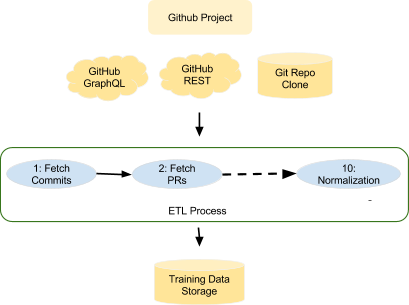
Diagram of ETL process
Steps 2 and 3 are done though an Extract, Transform and Load (ETL) process which consumes the REST GitHub API (V3), both REST and GraphQL and stores relevant feature data inside a MongoDB instance, which retrieves information from Github sources of the project PRs using the Github API. For computing Churn and Hotness we use a clone of the Github repo and a git client for comparing PR branches and the project destination branch. We also use Github GraphQL API (V4) to retrieve some user information including social connection (social_conn). GraphQL allows richer queries that span among different entities, like querying user social connections, for all authors of all pull requests for the specific project. Using GraphQL can help lessen the number of URL requests on the API. The following code excerpt shows how to pull paginated data from the MergedEvents for a particular PR. This is used to detect if a PR was merged or not.
{
repository(owner: nodejs, name: node){
name,
pullRequests(first: 100, states: MERGED) {
nodes {
id,
url,
timeline(last: 100) {
nodes {
... on MergedEvent {
id,
actor {
login
}
createdAt,
url,
}
}
}
},
pageInfo {
hasNextPage,
hasPreviousPage,
endCursor,
startCursor,
},
totalCount
}
}
}
However, we were unable to use GraphQL for all patterns due to lower rate limits which slows down the process of retrieving data. Also, we noted complex GraphQL calls are slower compared to their V3 API counterparts. The ETL process was designed to be resumable and restartable, since it can take several hours to run. We separate the ETL process in several tasks, which can be resumed or restarted at will. The ETL tasks are the following ones:
| 1 | fetchCommits
|
Gets all commits in the master branch of the projects using REST API |
| 2 | fetchPullRequests
|
Fetches all PRs metadata using REST API |
| 3 | fetchCommitDiffs
|
Clones git repository locally and all PRs source branches to compute Hotness and Churn |
| 4 | fetchUserEvents
|
Saves the latest User Events to help in computing user social connection. Was not used in the final feature set. |
| 5 | fetchUserInfo
|
Get User metadata using the GraphQL API |
| 6 | fetchIntegrators
|
Gets all project integrators by looking into the MergedEvents of the Pull Request |
| 7 | computeHotness
|
Using the local repo, makes diffs between PR source branch and destination branch to compute |
| 8 | guessCommitPRRefs
|
Guesses PR merge events using repo history. This step is specific to the NodeJS project, which closes PRs and merges them in a separate commit instead of using Github Merge feature. |
| 9 | setUsersId
|
Translates base64 encoded user info to allow PR data and User data to match. |
| 10 | Normalization
|
Merges all the data to generate training ready data. This generates a single table of features and classification (Merged/Not merged) |
Set of ETL Tasks for loading and normalizing data
Predictor building and Evaluation

Overfitting Electoral Precedence (source: XKCD)
After all the steps, the training data is ready to be processed into an ML algorithm of our choice. Steps 4 and 5 are done using the scikit-learn library. To avoid overfitting our model to our training data, we partition the PR feature data in two sets: training and validation. Our training data has 90% of the PRs, and the validation set the remaining 10%. We perform cross-validation using learning by splitting our training data in 10 groups using k-fold validation. We tried many predictors, including the following:
- Naive Bayes (Bernoulli and Gaussian)
- Decision Trees
- K Nearest Neighbors
- Linear Discriminant Analysis
- Logistic Regression
- Multi-layer Perceptrons
- Nearest Centroids
- Quadratic Discriminant Analysis
- Ridge Regression
- Support Vector Machines (SVC) (C Supported and Linear)
- Stochastic Gradient Descent (SGD)
- Passive Aggressive Algorithms
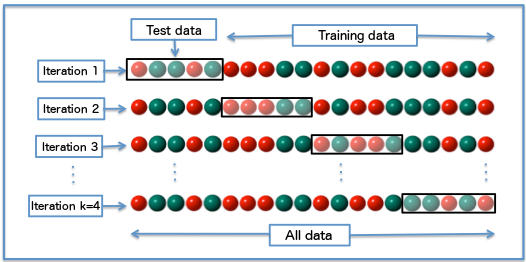
Diagram of k-fold validation with 4 groups. (source: Wikipedia)
{kind=link}
For our nodejs repository we gathered 10,200 PRs from November 2014 to November 2017. Our raw data had the following shape for the features. It is worth noting around 76% of recovered MRs were merged. That's a sizeable dataset to train most predictors.
created_
friday
|
description_
complexity
|
log_hotness
|
log_churn
|
is_integrator
|
|
| Mean | 0.172 |
134.500 |
1.147 |
5.944 |
0.498 |
| Std | 0.377 |
389.832 |
0.915 |
3.901 |
0.500 |
| Min | 0.000 |
1.000 |
0.000 |
0.000 |
0.000 |
| Max | 1.000 |
19,825.000 |
4.043 |
15.523 |
1.000 |
| PR Data Analysis | |||||||
has_tests
|
success_rate
|
social_conn
|
requested_review
|
was_merged
|
|||
| Mean | 0.721 |
0.514 |
4.973 |
0.019 |
0.758 |
||
| Std | 0.448 |
0.221 |
1.801 |
0.138 |
0.428 |
||
| Min | 0.000 |
0.000 |
0.000 |
0.000 |
0.000 |
||
| Max | 1.000 |
1.000 |
11.823 |
1.000 |
1.000 |
||
After testing a total of 21 classifiers, we got accuracy rates ranging from 77% to 88% on our training data. We ended up choosing a C Supported SVC, which got a mean of 87% accuracy on our 10 cross-validations. It is a good number for the training data, but the real measure is to test our model with the test data. The SVC model performed a little worse in the test dataset reaching an 78% precision, which is still acceptable.
| Precision | Recall | F1 score | Support | |
| Not merged | 0.76 |
0.22 |
0.34 |
264 |
| Merged | 0.78 |
0.98 |
0.87 |
753 |
| Average | 0.78 |
0.78 |
0.73 |
1017 |
Precision metrics on test data
Conclusions and Future Improvements
Our experiments have shown it is possible to build a predictor to accurately predict MR, helping lighten project integrators workload when there is a large queue of MR waiting to be evaluated. Time-based data, like MRs, need special handling to make predictions more accurate. MR acceptance criteria change over time and filtering out old MRs might be a good idea. Extending the feature set for the predictors to include more information will surely make predictions more accurate. Extracting data from Github projects to feed the data to the predictor can be a long running process that requires special handling, because internet disconnections and API limitations may lead to interruptions and the need to recover the process. Finally, each project has different merging mechanisms not using the built in "merge" feature of Github and might need to run CI for the MR to be accepted, meaning that this should be accounted for in the predictor. Ultimately there is no one-size fits-all solution, but with the right tooling an MR prediction app can be developed for every Github project that has enough MR under its belt. The source code used to develop the model in this article is available on https://github.com/sophilabs/pullreq-ml.
References
-
Y. Yu, H. Wang, V. Filkov, P. Devanbu and B. Vasilescu, "Wait for It: Determinants of Pull Request Evaluation Latency on GitHub" 2015 IEEE/ACM 12th Working Conference on Mining Software Repositories, Florence, 2015, pp. 367-371. ↩
-
Gousios, Georgios and Pinzger, Martin and Deursen, Arie van, "An Exploratory Study of the Pull-based Software Development Model" Proceedings of the 36th International Conference on Software Engineering, pp. 345-355 ↩
-
Jason Brownlee, How to Convert a Time Series to a Supervised Learning Problem in Python, Retrieved from machinemastery.com, May 8, 2017. ↩

Django Girls Montevideo: Working to Close the Gender Gap in Software Development
Women are scarce in engineering, in fact, 97% of the resumes we receive come from men. In launching Django Girls Montevideo, we strive to do our part to contribute to gender equality.

Elixir: An OTP walkthrough
In the next series of posts, we'll be talking about what OTP is, and explain one of the biggest advantages of using it to help struct your code, eliminate boilerplate,, and more by using the OTP framework.
Photo by rishi.
Categorized under research & learning / machine-learning.